
과학자들은 AI를 사용하여 음성 샘플에서 노래할 수 있는 새로운 신경망을 만들었습니다. 중국 개발자의 알고리즘은 그 사람의 평소 연설 녹음을 기반으로 한 사람의 노래 녹음을 합성하거나 반대로 수행하여 노래를 기반으로 음성을 합성할 수 있습니다. 알고리즘의 개발, 교육 및 테스트를 설명하는 기사가 있습니다. 출판 arXiv.org에서
최근에는 다음과 같은 음성 합성을 위한 신경망 알고리즘이 개발되고 있습니다. 웨이브넷 , 실제 사람과 구별하기 어려운 시스템을 만들 수 있습니다. 예를 들어, 2018년에 Google 보여주었다 리얼하게 말할 수 있을 뿐만 아니라 음성을 확인할 수 있는 사람의 소리(예: “음”)를 삽입할 수 있는 좌석 예약용 음성 비서. 결과적으로 회사는 대화 시작 시 사람이 아님을 경고하는 알고리즘도 가르쳐야 했습니다.
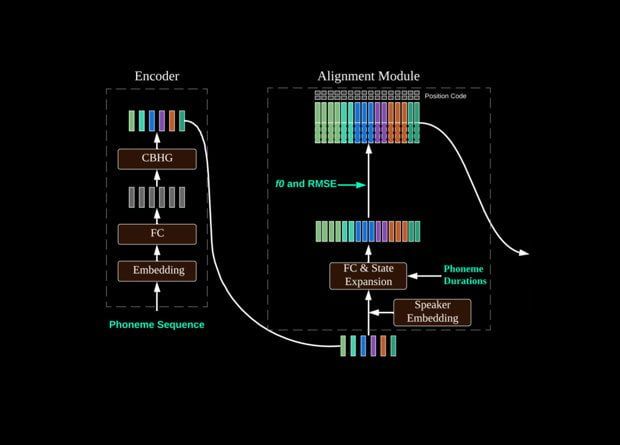



다른 신경망 알고리즘의 경우와 마찬가지로 음성 합성 시스템의 성공은 주로 아키텍처와 관련이 있지만 대부분 교육에 사용할 수 있는 많은 데이터와 관련이 있습니다. 노래를 합성하는 시스템을 만드는 것은 겉보기에는 비슷한 작업이지만 실제로는 사용 가능한 데이터 양이 현저히 적기 때문에 훨씬 더 복잡합니다.
노래 생성 시스템을 연구하는 많은 개발자들은 최근 알고리즘을 가르치기 위해 노래 샘플의 양을 줄이는 방법을 택했으며 이제 Tencent의 Dong Yu가 이끄는 중국 연구원 그룹은 음성에서 사실적인 노래 오디오 녹음을 생성할 수 있는 시스템을 만들었습니다. 시료.
https://www.youtube.com/watch?v=AnazWGADtnk
알고리즘은 Tencent의 이전 개발인 DurIAN 신경망을 기반으로 하며 실제 비디오 텍스트를 기반으로 말하는 발표자와 함께. 이제 그들은 오디오 샘플을 기반으로 음소를 생성하는 새로운 음성 인식 장치를 DuarIAN 앞에 배치했습니다.



